
Attempting to draw conclusions about the author of a text based on traits of the text alone has a long tradition. It has been a topic of interest in forensics (identifying perpetrators or revealing forgeries), literary studies (authorship identification) and psychology (from psychoanalysis to modern customer/consumer behavior studies). In 15th Century Italy, Lorenzo Valla proved the forgery of the Donation of Constantine based on anachronistic word choice (8th, and not 4th, century A.D.) and poor grammar. Contending the authorship of certain texts previously attributed to Shakespeare goes back to the end of the 17th Century and builds on the philological methods stemming from biblical and classic studies, developed in the Renaissance period, analyzing language style (word choice and grammar). In the 20th Century, psychoanalytical techniques based on language were introduced by Freud and later Lacan, the latter, ironically, criticized for his obscure writing style.
During the latest decades, due to the upcoming of machine learning technology, automated author identification and profiling has reached new heights of interest with scientists (linguists, psychologists) as well as healthcare, forensic, political and corporate-economic stakeholders. The textual features looked at are usually either content words (nouns, adjectives, adverbs, verbs), function words (e.g. pronouns, prepositions, conjunctions) or both, allowing analyses of “content” and “writing style”. Larger text corpora have been developed, spanning from writing assignments to spontaneous writing produced in different contexts (e.g. customer reviews, Facebook posts), which get correlated with information about the authors’ demographics (age, gender, education, ethnic and geographical origin, native language, etc.) as well as personality.
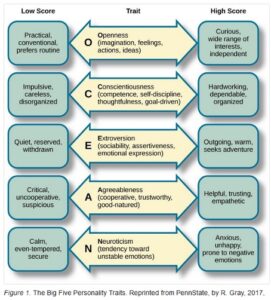
The latter is measured according to different established taxonomies based on scaled personality traits, either by self-report or questionnaire testing. A frequently used taxonomy is the ”Big Five” model (see figure 1 below). This model, developed by McCrae & Costa 1989, measures the presence or absence of five basic traits: openness (conventional, prefers routine vs. wide range of interest, independent), conscientiousness (careless, disorganized vs. dependable, organized), extraversion or extroversion (quiet, withdrawn v. outgoing, warm), agreeableness (uncooperative, suspicious vs. helpful, empathetic) and neuroticism (calm, even tempered vs. anxious, prone to negative emotions). The machine learning methods in question seem to become more and more accurate, since human beings, apparently, are much more predictable than we would like to think.
But what about ourselves as readers of text? As Annette Markham already showed decades ago in her pioneering research on early online communication, we automatically ascribe demographic and personality features to the authors of texts we read, and sometimes, we get it terribly wrong. We are guided by default thinking, prejudice, and a bias that makes us expect that the other is very much like ourselves in some respects, e.g. as to skin color.
But what about concrete features of text? They do seem to influence some of our assessment. But which features do we build our assessments on? And do all types of features have the same effect on every reader? To answer this question, I performed a mini-experiment in my lesson on “Communicative conventions” in my class “Social Media and Communication” at the new ARTS supplementary program “Social Minds” at AU in spring 2021. 21 students (7 male, 14 female), both Danish and international, assessed the author’s personality of a now deleted, and hence anonymity protected, anti-vaccination Facebook post, based on the Big Five taxonomy.
The results of this experiment will be presented in part 2 of this blog “A mini-experiment on author personality assessment”.
Readings:
Argamon, Shlomo, Koppel, Moshe, Pennebaker, James W. & Schler, Jonathan. 2009. Automatically Profiling the Author of an Anonymous Text. Communications of the ACM 52(2):119-123, DOI: 10.1145/1461928.1461959
Camporeale, Salvatore I. 1996. Lorenzo Valla’s “Oratio” on the Pseudo-Donation of Constantine: Dissent and Innovation in Early Renaissance Humanism. Journal of the History of Ideas 57(1), 9-26. doi:10.2307/3653880
Markham, Annette. 1998. Life online: Researching Real Experience in Virtual Space. Boulder: Altamira Press.
McCrae, R. R., & Costa, P. T. 1989. Reinterpreting the Myers-Briggs Type Indicator from the perspective of the five-factor model of personality. Journal of Personality, 57(1), 17–40. https://doi.org/10.1111/j.1467-6494.1989.tb00759.x
Parker, Ian. 2005. Lacanian Discourse Analysis in Psychology: Seven Theoretical Elements. Theory & Psychology 15(2):163-182. doi: 10.1177/0959354305051361
Pennebaker, James W., Mehl, Matthias R., Niederhoffer, Kate G. 2003. Psychological aspects of natural language use: Our words, our selves. Annual Review of Psychology 54, 547-577.
Schwartz, H.A., Eichstaedt, J.C., Kern, M.L., Dziurzynski, L., Ramones, S.M., Agrawal, M., et al. 2013. Personality, Gender, and Age in the Language of Social Media: The Open-Vocabulary Approach. PLoS ONE 8(9): e73791. https://doi.org/10.1371/journal.pone.0073791
Smith, Emma. 2008. The Shakespeare Authorship Debate Revisited. Literature Compass 5(3): 618-632. https://doi.org/10.1111/j.1741-4113.2008.00549.x
Tausczik, Yla R. & Pennebaker, James W. 2010. The Psychological Meaning of Words: LIWC and Computerized Text Analysis Methods. Journal of Language and Social Psychology 29(1) 24–54, DOI: 10.1177/0261927X09351676
Ver Eecke, W. 2021. The unconscious emotive dimension of language: Freud and psychoanalysis on the mysterious ways of language. Journal of Theoretical and Philosophical Psychology. Advance online publication. https://doi.org/10.1037/teo0000183
Alexandra Kratschmer is an associate professor at the Department of Linguistics, Aarhus University, specialized among other things in text linguistics and discourse analysis.
 ”I read your Facebook post and (I think) I know who you are”, part 2: A mini-experiment on author psychology assessment
”I read your Facebook post and (I think) I know who you are”, part 2: A mini-experiment on author psychology assessment  A Brief History of the Canadian Language Museum or How a Posting on Linguist List Changed My Life
A Brief History of the Canadian Language Museum or How a Posting on Linguist List Changed My Life  The complicated femininity of “Sut Min Klit”
The complicated femininity of “Sut Min Klit”  Researchers hiding in fear of GDPR
Researchers hiding in fear of GDPR  When language becomes violence
When language becomes violence  Why has a rape only “allegedly” taken place?
Why has a rape only “allegedly” taken place?