
What would we do without the helpful voices in our GPS systems guiding us to our destinations? How would we look up esoteric facts without the silky voices of the virtual assistants on our phones? And how would we remember our belongings as we leave the train without a considerate voice reminding us to do so? Artificial voices suffuse our day-to-day worlds and fulfill practical functions, but where do these voices come from, and how do you ‘synthesise’ speech?
The first stones of the story of speech synthesis were laid over 200 years ago where mechanical devices produced speech sounds by emulating the complex structure of the human articulatory system. Technological innovations in the early 20th century then allowed for the properties of human speech to be encoded in electrical circuits. And finally, recent advances within deep learning, neural networks and artificial intelligence have improved the quality and naturalness of speech synthesis – to the extent that these machine-generated voices can be completely indistinguishable from those of real speakers.
The story of speech synthesis is a story of technological innovation, and the artificial voices of our modern world are underpinned by a rich narrative of failed attempts, misguided experimentation and scientific exploration. This three-part series of articles delves deeper into the historical origins of speech synthesis and details the trajectory of innovations within this field: from the talking tubes of the 18th century to the neural networks of modern times. The below article takes a closer look at the mechanical era of speech synthesis where scientists and inventors attempted to reproduce speech sounds by building talking machines.
The Mechanical Era of Speech Synthesis
The Basics of a Talking Machine
The first evidence of an attempt to build a speech synthesiser comes from a report submitted to a contest by the Imperial Academy of Science in St. Petersburg in 1780 (Story, 2019). Christian Gottlieb Kratzenstein, a physics professor at Copenhagen University, won the prize for his design of a machine that could produce five vowels: /a, e, i, o, u/. His device consisted of five resonant tubes made of ivory or baleen, one for each of the vowel sounds (as shown in Figure 1 below), and a reed to act as a sound source. Kratzenstein shaped the tube-like resonators to alter the sound source in such a way that they would produce approximations of the particular vowel sounds. The shapes of these resonators bear little resemblance to the human vocal tract, which suggests that he designed these constructions largely by trial and error.
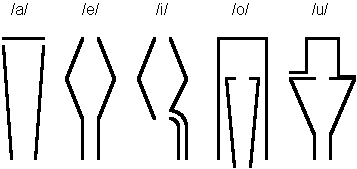
Despite winning first prize at the contest, Kratzenstein shows a lack of understanding of the basic anatomy of speech production (Ohala, 2011). In the first part of his report, for example, Kratzenstein incorrectly names the epiglottis (i.e. the flap of cartilage behind the root of the tongue) as playing a fundamental role in the production of all human speech sounds. He also incorrectly rejects the hypothesis that pitch depends on the vocal folds, arguing that their mass and thickness would prevent them from being able to vibrate at high frequencies. Kratzenstein’s vowel synthesiser, then, marks the onset of technological innovation within the field of speech synthesis, but his overall contribution to speech science can be considered modest at best.
From Hoaxer to Speech Scientist
At around the same time as Kratzenstein constructed his talking machine, Wolfgang von Kempelen developed his Acoustical-Mechanical Speech Machine (Story, 2019). Von Kempelen, a Hungarian civil servant and inventor, designed his device with the aim of providing the deaf with a means to produce speech. In contrast to Kratzenstein, the individual components of von Kempelen’s machine closely resembled the human vocal tract: a bellows acted as the human lungs, a wooden box served as the windpipe, a reed acted as vocal cords, and a leather tube played the role of the oral cavity. The machine featured an extra chamber for nasal sounds as well as control levers for specific consonants, as shown in Figure 2 below.
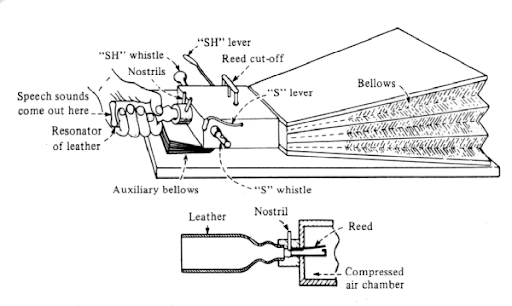
In order to produce a sound, the operator of the machine had to manage an astounding number of moving parts. The operator would use his or her left elbow to depress the bellows and initiate vibration of the reed, while the palm of the left hand had to sculpt the leather tube into different configurations – and at the same time, the right hand had to operate control levers to trigger such properties as nasality (for /n/ or /m/) or sibilance (for /s/ or “sh”). Due to the complexity involved in balancing its moving parts and its limited air supply, the machine could at most produce isolated words.
Von Kempelen’s machine was received quite negatively by the public, mostly due to his reputation from earlier transgressions: Before von Kempelen constructed his talking machine, he claimed to have invented a chess-playing automaton that could win a game of chess against any human opponent. This would indeed have been an impressive invention, if it did not simply involve concealing a human chess-playing expert inside the machine. As a result of this mischievous hoax, the public at first assumed that this talking machine was a sham as well. Von Kempelen deserves credit for his contributions to the study of speech synthesis; he wrote a book that details his scientific experiments of over twenty years, showing the value of using mechanical models of speech production to investigate the structure of speech sounds.
A Macabre… I mean… Fabulous Talking Machine
Inspired by von Kempelen’s talking machine and his writings on speech sounds, a German-born inventor by the name of Joseph Faber set out to build an even more advanced speech synthesiser. Faber’s most significant improvement upon von Kempelen’s original machine was to install a series of six adjustable metal plates in a resonant chamber to emulate the front and back cavities of the human vocal tract. The raising and lowering of these individual metal plates allowed for the production of the fine-grained airflow distinctions required for speech sounds. Faber connected all of the reeds, whistles, resonators, tubes, and shutters by coupling everything to a series of levers that could be controlled by a keyboard with seventeen keys. The machine was said to be able to produce any vowel and consonant combination required to speak any European language, and with a skilled operator, to be able to sing “God Save the Queen” (Ramsay, 2019). Faber mounted his speech synthesiser on a table to allow people to inspect the complex mechanism, and attached a female mask at the helm, as shown in Figure 3 below.

In the 1840s, Faber started to perform with his talking machine in front of audiences. Euphonia, as the talking machine was later named, must have been quite a bizarre sight to behold. One of the theatre managers, John Hollingshead, provides a first-hand account of the experience and states that Euphonia’s speech radiated “slowly and deliberately in a hoarse sepulchral voice (…), as if from the depths of a tomb” (Hankins & Silverman, 1999).
Despite Euphonia being the most advanced talking machine of its day, Faber’s demonstrations of Euphonia were met with muted interest by the public. In a strange quirk of history, however, Alexander Melville Bell, a Scottish professor of speech science and one of the few admirers of Euphonia, happened to be in the audience at one of Faber’s demonstrations of his talking machine in London in 1846. The unconventionality of the talking machine had impressed Melville Bell to the extent that he would later challenge his son, Alexander Graham Bell, and his brother to build a similar contraption – they eventually succeeded and their machine could cry “mama” (Vlahos, 2019). This experimentation with speech synthesis likely laid the groundwork for Alexander Graham Bell to invent the most successful speech reproduction device in human history: the telephone.
Faber’s Euphonia never amounted to being anything more than a sideshow spectacle. Disheartened by his failure to achieve recognition for his advanced talking machine, Faber destroyed his invention and took his own life in the 1860s, although there is some uncertainty surrounding the circumstances of his death. Because Faber never produced a written account of his design, the “Fabulous Talking Machine” was quickly forgotten by the public.
The End of the Mechanical Era
Already in the first half of the 1800s, the scientific investigation of speech synthesis had started shifting into the realm of physical acoustics, where scientists to a greater extent explored the structure of speech sounds by looking beyond the vocal organs. The trial-and-error methods of Kratzenstein, von Kempelen and Faber gave way to scientific rigour and experimental investigation. Willis (1829), for example, studied the acoustic effects of altering the tube lengths of organ pipes and discovered that he could generate a series of vowel sounds by enhancing particular harmonic components of the sound source. This construal of speech sounds as combinations of frequency components would entertain acousticians until modern times. This sets the stage for the next part of the story: The Electrical Era of Speech Synthesis.
Reading Recommendations
- If the absurdity of Faber’s Euphonia strikes you as interesting, I’d recommend that you take a closer look at the ‘Talking Heads’ of Abbé Mical. I couldn’t cover that story here due to length restrictions.
- If you want to know more about the most important acoustics experiments of the 19th century, I’d recommend having a look at Wheatstone (1837), Helmholtz (1875), Koenig (1873), and Miller (1916).
List of References
Flanagan, J. L. (1972). Speech synthesis. Speech Analysis Synthesis and Perception. Springer Berlin Heidelberg.
Hankins, T. L., & Silverman, R. J. (1999). Instruments and the Imagination. Princeton University Press.
Helmholtz, H. (1875). On the sensations of tone as a physiological basis for the theory of music. London: Longmans, Green, and Co.
Koenig, R. (1873). I. On manometric flames. The London, Edinburgh, and Dublin Philosophical
Magazine and Journal of Science, 45(297), pp. 1-18.
Miller, D. C. (1916). The Lowell lectures: The science of musical sounds. New York: MacMillan and Co.
Ohala, J. J. (2011). Christian Gottlieb Kratzenstein: Pioneer in speech synthesis. Proc. 17th International Congress of Phonetic Sciences, pp. 156-159.
Ramsay, G. J. (2019). Mechanical Speech Synthesis in Early Talking Automata. Acoustical Society of America, 15(2).
Schroeder, M. R. (1993). A brief history of synthetic speech. Speech Communication, 13(1-2), 231-237.
Story, B. H. (2019). History of Speech Synthesis. In W. Katz & P. Assmann (Eds.) The Routledge Handbook of Phonetics (pp. 9-32). Routledge.
Vlahos, J. (2019). Talk to Me: Amazon, Google, Apple and the Race for Voice-Controlled AI. Random House.
Wheatstone, C. (1879). Reed organ-pipes, speaking machines, etc. The scientific papers of Sir Charles Wheatstone. London: Taylor & Francis, 348-367.
Willis, R. (1829). On the vowel sounds, and on reed organ pipes, Transactions of the Cambridge Philosophical Society, 3, pp. 231-268.
Chris Cox has studied Phonetics & Phonology at the University of York and is currently employed as a PhD student at Aarhus University, where he investigates the role of infants’ vocal exploration in the process of early language acquisition.






The raising and lowering of these individual metal plates allowed for the production of the fine-grained airflow distinctions required for speech sounds. Faber connected all of the reeds, whistles, resonators, tubes, and shutters by coupling everything to a series of levers that could be controlled by a keyboard with seventeen keys. This would indeed have been an impressive invention if it did not simply involve concealing a human chess-playing expert inside the machine.