
![]()
In late February 2020, I found myself sitting at a table in the Interacting Minds Center with a diverse group of Aarhus University researchers discussing how to research the social and behavioural aspects of the emerging Covid-19 epidemic. The expertise of the other researchers spanned media and information studies, anthropology and ethnography, religious studies, political science, and computer science. I represented linguistics. At the time, Covid-19 had not (to our knowledge) reached Denmark, and it was still at least a week before the WHO would officially designate it a global pandemic. We suspected that this virus might have significant consequences for our lives, but we could never have imagined how much and how quickly.

Just weeks later, on March 11th 2020 (two years ago today), Denmark entered its first lockdown and the HOPE Project was born, with a grant from the Carlsberg foundation. HOPE stands for How Democracies Cope with Covid-19, and it uses a combination of survey, ethnographic, and digital media data to comparatively monitor social and behavioural aspects of the pandemic in several different countries, including the Nordics, the US, the UK, France, Germany, the Netherlands, and Hungary. You might be wondering what a linguist could contribute to this project. While the HOPE project falls outside traditional linguistics research topics about language systems or grammars, much of the data we work with is linguistic in nature, including interview transcripts, news coverage, and social media posts. Therefore, methods in computational linguistics and Natural Language Processing are essential for extracting, summarizing, quantifying, and analysing information from these vast amounts of textual natural language data.

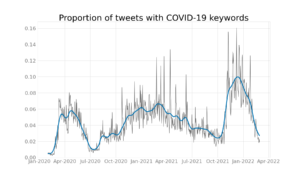
Denmark has attracted international attention in recent months due to its omicron surge (during which an estimated 60% of adult Danes have been infected) and its controversial decision to lift all restrictions on February 1st in the midst of record-high infection rates. To track what the world is saying about Denmark during this time, we have also collected all English language Tweets which mention Denmark and corona/covid/omicron since November 2021. You can interact with these results here: https://webservice2.chcaa.au.dk/hope-twitter-analytics/en/
A feature of European data protection laws (GRPR) is that social media posts usually fall under the class of ‘sensitive data’, which means that we can publish quantitative results but we cannot publish individual Tweets. This can be frustrating when one wants to examine and reason about individual Tweets. I recently came up with a rather experimental and unorthodox way around this hurdle: to train a large neural language generator model (GPT-Neo) on our datasets of positive, neutral, and negative English Tweets about the Danish covid-19 situation to produce novel tweets that approximate patterns in the training data. This allows us to publish examples of the kinds of arguments and claims people make (and the language they use) in detail, without compromising privacy.
We will shortly release another web app where members of the public can interact with the GPT-Neo model by feeding it inputs (e.g. “Denmark’s covid-19 policy is…”, “Vaccines are…”) and let the model auto-complete the text. (Similar to the Write with Transformers app based on GPT-2 here: https://transformer.huggingface.co/doc/gpt2-large).
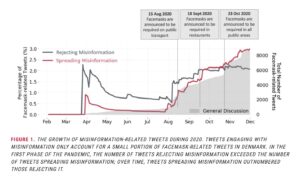
To date, we have collected more than 40,000 public Danish Facebook posts, 30 million Danish tweets, 60 million Swedish tweets, and 15 million Norwegian tweets from February 2020-present. The social media datasets alone represent a significant contribution to both the historical record and to available digital corpora for linguistics research, and have contributed to important public resources for Danish like the Danish Gigaword Project, a curated collection of over a billion words of Danish text from a large variety of different registers and genres. Our Twitter data has also recently been used in a study on mask-related misinformation in Denmark.
In addition, the analyses needed for the HOPE project have required us to improve and developing existing natural language processing models and methods for under-resourced languages like Danish, including improving Named Entity Recognition and co-reference resolution through new annotation collections. We also had to come up with novel techniques for cross-linguistic application of tools like sentiment analysis.
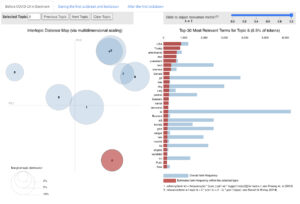
We have also gained access to comprehensive daily news coverage for the pandemic period from all major Danish, Norwegian, and Swedish newspapers. For the analysis of daily news media, we have relied heavily on a technique called topic modeling to automatically group documents according to their topical similarities. We published an interactive dashboard which allows people to explore how the topical distribution in seven major Danish newspapers differed before, during, and after the first lockdown in 2020.
Topic models were also used to group together crowdsourced reflections on the pandemic’s impact on people’s daily life in the interactive art project We Used To, a collaboration between HOPE and Studio Olafur Eliasson in Berlin.

In our new media research, we have also used topic models as latent (i.e. hidden) variables in an analysis of information signals in the daily news cycle. Intuitively, we treat news media coverage of Covid-19 as a natural experiment in how cultural information systems respond to catastrophes. Because variation in newspapers’ word usage is sensitive to the dynamics of natural and socio-cultural events, it can therefore be used to measure how a catastrophic event disrupts the ordinary information dynamics of news media. You can read our preprint about this approach or watch a video of my talk at last year’s Covid-19 Datathon.
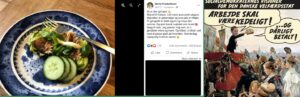
Finally, I have recently had the pleasure to collaborate with fellow AU linguist Alexandra Kratschmer to combine computational methods and traditional discourse analysis to analyse the rhetorical strategies used by Mette Frederiksen on her public Facebook page during the pandemic period, and the public uptake of her posts (including the infamous “makrelmad” post, which launched a thousand memes). Please watch Lingoblog for a future joint post about this work.
When I became a linguist, I never imagined that I would spend two years contributing to an interdisciplinary research project on an infectious virus, producing reports that are consulted by the Danish Statsminister and parliament the purpose of policymaking decisions. But the experience has been nothing but rewarding. Being able to lend my skills as a computational linguist to a project with such urgency and social impact has given me a sense of meaning during these difficult two years. Another wonderful aspect of HOPE is that it has allowed me to hire, supervise, and collaborate with many talented students from the programs in Linguistics, Cognitive Science, Cognitive Semiotics and English at AU, who have applied their language and linguistics expertise and coding skills.
Nevertheless, I hope the urgent need for pandemic media monitoring will soon come to end, so I can turn my attention back to core linguistics topics that are close to my heart—topics like the semantics of property concepts and variation in sound symbolism systems in West African languages. Maybe you will get to hear about these in a future Lingoblog column.
Rebekah Baglini works as a computational linguist at Aarhus University, associated with the Department of Linguistics at Institute for Communication and Culture and Interacting Minds Center.
 The first ever Twitter-conference on linguistics is taking place this Saturday!
The first ever Twitter-conference on linguistics is taking place this Saturday!  A Brief History of the Canadian Language Museum or How a Posting on Linguist List Changed My Life
A Brief History of the Canadian Language Museum or How a Posting on Linguist List Changed My Life  LingoLit: A Linguist’s Quarantine Reading Guide
LingoLit: A Linguist’s Quarantine Reading Guide  Karl Verner, world-famous linguist – a former student from Aarhus Cathedral School. Part 1 Karl Verner, world-famous linguist – an former student of Aarhus Cathedral School. Part 2 Karl Verner, world-famous linguist – a former student from Aarhus Cathedral School. Part 3
Karl Verner, world-famous linguist – a former student from Aarhus Cathedral School. Part 1 Karl Verner, world-famous linguist – an former student of Aarhus Cathedral School. Part 2 Karl Verner, world-famous linguist – a former student from Aarhus Cathedral School. Part 3
Thanks a lot for this great report, Rebekah! There lie huge opportunities in the privacy-friendly applications GPT-Neo and Transformer, which I here heard about for the first time. They will allow to objectivize the privacy protection methods of qualitative data alienation and fabrication, already suggested by Annette Markham in 2012 (“Fabrication as Ethical Practice”) and still not universally accepted as legitimate, and give qualitative digital media analyses a very much needed ally.