
Gender equality in machine translation
Many times I have heard of my weird – or original, as I like to say – mother tongue, Finnish. It belongs to the same language family as Hungarian but is geographically isolated in the North, and not related to the neighbouring Nordic languages nor Russian. However, I’ve always been proud of the uniqueness of my language.
Each language has its unique way of capturing and categorizing the world, but in the case of Finnish, one could rather talk about non-categorizing: Finns don’t have articles nor grammatical genders, like “a” and “an” in English, or like feminine and masculine forms in French. In fact, there is no apparent gendering almost at all in the language. Only one personal pronoun, “hän”, is used to refer to both he and she. And it is not a new invention, like the Swedish hen in addition to han and hon for males and females, respectively, but natural to the language.
Imagine, which possibilities this brings in the use of the language. You could write a whole novel about “hän” without letting know, if “hän” really is a he or she. That intriguing decision is up to the reader and leaves a lot of freedom. This also leads to freedom in every-day situations. You don’t need to decide whether someone you encountered was a woman or a man. S/he was simply “hän”.
But this freedom turns into a problem when it comes to translating. How to fit a gender-neutral language into another language having specific gender roles? This is especially difficult when the sentences to be translated are taken away from the context. Or when the translations are done by a machine. As Finnish is a small language with 14 different grammatical cases for nouns, machine translators aren’t always very accurate. Sometimes it’s amusing. For example, the Finnish phrase meaning “I ate French fries” results in “I ate Frenchmen”.
However, when it comes to genders, machine translations become an equality issue – and I’m not the only Finn having noticed it. Research has found that algorithms learn to replicate human gender biases reflecting stereotyped gender roles. This bias is obvious with professions. Based on the common stereotypes of women ending up secretaries and men lawyers, the same results can be found in machine translations.
A research project conducted at Aarhus University tested this finding by typing simple Finnish sentences including the personal third pronoun “hän” and a profession in Google Translate, and got results like:
“She is a nurse.”
“She is a secretary.”
“She is a kindergarten teacher.”
“He is an engineer.”
“He is an architect.”
“He is a farmer.”
Quite stereotypic, isn’t it? Some results were surprising, though. For example, she was a guard and a mechanic, and he was a receptionist.
But how does Google Translate then make these decisions? The system is originally based on the principles of statistical machine translation. It means that the program is trained with large corpora of texts, and it detects frequencies of word patterns. Thus, words that often occur together are also translated together. The physical distance between words directly affects the translation quality because the machine mainly targets and looks for subsequent words.


Thus, the algorithm detects the similarity between women and nurse, but when the adjective “skilful” is added, this connection is lost, and the gender translation is based on the adjective, that is apparently more related to masculine “he”. It isn’t difficult to understand why this could make feminists angry.
The failure in distance and logic relations is even more apparent in the second example. The incongruency in the gender of two successive sentences is an error people wouldn’t do.
Following the principles of latent semantic analysis, semantic similarity of word pairs is measured in word vectors. Small cosine values of vectors represent words that are not related in meaning – that do not usually occur in the same context – and conversely, large cosine values indicate close semantic similarity.
The correlation between semantic distance of some professions and adjectives to genders was then analysed. Although many stereotypes, such as nurses being semantically closer to women and software developers to men corresponded to the machine translations, the correlation between the personal pronouns and professions wasn’t confirmed. The correlation coefficient was negative, as expected, but not significant. One apparent reason was that “he” is often used as a default pronoun in the English language. The high frequency of this pronoun in several contexts makes it less related to any particular word. Thus, the absolute semantic distance doesn’t reveal everything about the related gender in English.
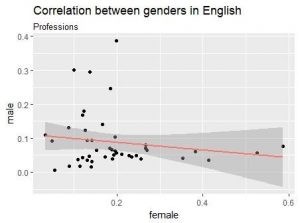
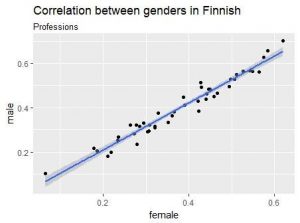
Semantic distances of professions to male and female genders. The results in Finnish are highly correlated, meaning that the semantic distance to both genders is quite equal, whereas in English, the distance to one gender increases when the other decreases, indicating that at least some professions are gender-biased.
But this doesn’t mean that Finnish people wouldn’t be gender-biased. When Finns were asked to rate how probably they would translate the gender-neutral pronoun “hän” into “she” or “he” with the same professions and adjectives, they made gender-biased choices. Although with adjectives Finns preferred to remain gender-neutral, the judgements of professions reflected the machine-translated stereotypes.
In fact, a surprising finding indicates that Finnish might be a more severely biased language despite its gender-neutral appearance. Prewitt-Freilino, Caswell, and Laakso (2012) suggested that languages having natural genders, such as French or Spanish, might actually have a more positive impact on gender equality. Having masculine and feminine forms of words enables taking both sexes into account and creating gender-symmetrical terms. In contrast, seemingly gender-neutral languages like Finnish might be more difficult to make gender-equal. The implicit associations of professions with genders are almost impossible to debias. Since the language doesn’t imply genders, there is no way of pointing out the biases and thus correct them in grammatical terms. Bosses remain men as long as the bias remains in Finnish people’s mental associations
Hence, it is easy to claim that machine translations are biased, but it is much more difficult to correct the problem. It seems that the problem is rooted somewhere deeper in our society. It is a statistical fact that there are more female nurses and male farmers than vice versa. We have created the biases in our languages. An ideal translation is grammatically correct and aligned in meaning. So, how can one say that a translated result of a woman secretary is wrong? How to correct a translation if it is just reflecting the reality?
The developers of Google Translate among other machine translation systems are aware of these problems and trying to improve the quality of translations. In 2016, Google launched a neural machine translation system that is based on sub-word units and two recurrent neural networks, trying to get over the simple statistical and phrase-based approach to translating. Perhaps the development of debiasing algorithms can in fact help us to tackle the problem of gender biases in the society.
Telma Peura is a 2nd year Cognitive Science student at Aarhus University, especially interested in cognition and its relation to languages.






For those who can read Danish, see also on Lingoblog, on related topics:
https://www.lingoblog.dk/koensneutrale-stedord/
https://www.lingoblog.dk/they-brugt-som-entalsform/
https://www.lingoblog.dk/han-hon-og-hen/