
Last year I was contacted by someone who claimed to have deciphered the Voynich manuscript. This manuscript is one of the big enigmas of medieval history and, for that matter, linguistics. No one has yet been able to decipher it, and many have tried. It is written in a totally unknown script in an unidentified language.
The manuscript is more than 500 years old. It has been publicly available for a century, and now it is also available online. Nobody has been able to translate the manuscript; there have been many proposals, but all have been rejected. People have claimed it could be written in a form of Hebrew, in a Romance language, in an earlier form of Romani, an Indic language, or even in a language from another planet. Medievalists are at a loss. Cryptographers—specialists in secret writing—have broken their brains on it. Linguists have tried as well, but all in vain.
In this contribution I will argue that the manuscript is in fact not interesting at all for language nerds.
As a teenager, a friend and I challenged each other in writing short texts in secret scripts, and we became better and better in deciphering them, while we also improved our skills in making our codes more complicated. We have not managed to decipher the Voynich manuscript. My friend, Eric, became a car mechanic and I became a linguist. We both do something useful for society.

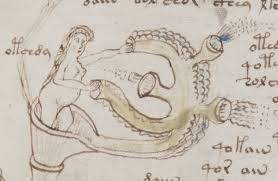
The Voynich manuscript is written on parchment that is dated to the first half of the 15thcentury. No doubt about that age. The text and illustrations could be newer, but could be from the same time as well. But other than that, only mysteries remain. Who wrote the manuscript? In which language? What is it about? What is the meaning or reference of these strange drawings of dragons, bathing naked ladies and maps of known and unknown places? Why are there no corrections in the manuscript?
As a linguist, one is of course curious about the text, and one wants to know whether it is written in a known or unknown language. As the manuscript contains 288 pages, it is certainly not the lack of material that has hindered the interpretation of the text. By comparison, Linear B, a syllabic script which predates the Greek alphabet by several centuries, was deciphered mainly on the basis of short inscriptions on clay tablets, not a book-length manuscript.
How does one go about deciphering a script and text like the one in the Voynich manuscript? One can use the number of signs (letters) in the text, the length of the different words, the combination of the signs and recurrence of patterns as clues. The “words” (let us assume they are in fact words) are separated by spaces (which is, by the way, not the case in all old texts). One can hypothesize that there should be recurrent parts of words that would be, for instance, case endings on nouns, as one founds them in Russian, Latin and Greek. In the beginning, there could be derivational prefixes as we find them in English, such as un- and re-. One could also try to identify recurring noun class markers as in Bantu languages, verbal inflections such as English -ed or Spanish-mos, or plural suffixes like English –s. We know that most languages of the world have them. One would therefore expect that such parts of words in the end and perhaps also the beginning would be repeated throughout the text, as in any natural text. There are only few languages that put such elements in the middle of a word.
First, one has to find out what kind of script it is. You want to establish whether the script is an alphabet (in an alphabetical script, each speech sound is assigned, in principle, one letter symbol, as in English, German or Spanish, and both vowels and consonants are written, and always separately), an abugida(each symbol denotes a consonant-vowel combination, like ka or si) or an abjad, a writing system with only consonants (srprsngl, wth nl cnsnnts,nglsh snt tht dffclt t rd), or a writing system where each symbol denotes a meaning. In Chinese, one written symbol may represent “house” or “horse” or “mother”.
Chinese has many thousands of such symbols because they mainly denote meanings, syllabic scripts have between 35 and 100 symbols for syllables, abjads between 15 and 30 consonant symbols, and alphabets roughly between 20 and 30 symbols for vowels and consonants. Thus, the number of symbols gives an indication of what writing system is used.

In the Voynich manuscript, there are between 25 and 30 individual symbols, which would mean that it is either an alphabetic script, or a consonantal script (abjad), and in the latter case it would be a language with many consonants. If it were an alphabetic script, the language would have a rather average number of speech sounds. That is then the most likely bet. But is an alphabetical script more likely than other types of script?
Only abjad or abugida writing systems are likely to have been invented spontaneously, but not an alphabetic system. Alphabetic writing has in fact only been invented once (!) in the universe, or at least on earth (we still lack data from other planets). The alphabet with consonants and vowels was an innovation by the Greeks, who added vowels to a Semitic writing system that only represented consonants. From the Greek alphabet, the Roman, Runic and Cyrillic alphabets have been derived, and scholars agree that even the quite different Ogham, Armenian and Georgian scripts were inspired by existing alphabets like those for Greek or Latin.

There is also a possible connection between word length and abjads. If all symbols in the script would represent consonants, i.e. the manuscript is an abjad, then the words in the language of Voynich would on average be quite long. In fact, the sequences are probably on average longer than would be expected for any language written with an abjad. Thus it is probably not an abjad.
When people are inspired to make their own writing system, they then typically make a syllabic writing system, especially if the syllable structure is simple, as when each consonant is always followed by a vowel in a word. Thus, the Indians, the Cherokees, the Ndyukas, Vai Africans of Liberia, Sumerians, etc., they all invented scripts, and they all wrote either only consonants, or, more often, only consonant-vowel combinations. Thus, if Voynich is written in an alphabetic script, then it is most certainly created by a person familiar with alphabetic writing used for other languages. Otherwise this person would have invented a syllabic writing system or an abjad.

Now that we have established that it is most likely an alphabetic writing system, the next step to explore would be to hypothesize that the text is written in an existing or known language, but in a different script than normally. Thus, one assumes that each sign represents a letter in an existing language, but it has been transliterated into another script. This has been tested, and none of the more than 300 languages tested provided a match. Of course, one has to remember that it is a medieval language, which may have been quite different from the language it evolved into (medieval Dutch and English, for example, are almost unreadable to modern speakers). On the other hand, computers are reasonably good at grouping languages according to families based on sound systems and letter frequency. The four languages that came closest (and there are always languages that come closest) were Hebrew, Arabic, Malay written in Arabic script, and Amharic (a language of Ethiopia which is written using a syllabic script).
One can also check average word length. In languages like Greenlandic, for instance, words are longer than in European languages, whereas Chinese words are much shorter. Words that consist of several parts (e.g. morphemes such as prefixes and suffixes), like Greenlandic, tend to be longer than those in languages with words that are just one syllable long, such as Chinese. The average word length for the Voynich manuscript appears quite similar to those of English and Latin, which again suggests that it would be written in an alphabet rather than an abjad, and that the language type is not polysynthetic like Greenlandic, nor isolating like Chinese. Rather, the word length is more in between, like European or Middle Eastern languages.

Linguists also know that some speech sounds are universally more frequent than others, and that knowledge about the languages of the world can be used to suggest the values of the letters. The vowel sound /a/ is more frequent than /e/, and the consonant /m/ is found in most languages but the consonant /f/ is much rarer. I am not aware, however, of studies that have used this knowledge systematically for the Voynich manuscript, but some people have used this information intuitively.
Another possibility is to look at the distribution of sounds within a word, assuming that each letter sign in the text represents a sound. One can, for instance, try to figure out which letters are most likely vowels and which ones consonants, by looking at which letters or symbols occur where in the words. In linguistics, we call this phonotactics. There are letters that only appear in certain positions, and it is not uncommon for languages to have sounds that do not appear in all positions in the word — in most languages, for example, no word can end in -tr. The distribution of letters in the manuscript has been studied, and the results seem to point to the possibility of a natural language. On the other hand, researchers have also observed that certain letters are much more frequent in some parts of the text, and even to such an extent that it is suspicious. This is typically found in fake language.
One can also investigate a text to see whether it obeys Zipf’s law: in the 1930’s, George Kingsley Zipf observed that there is a correlation between word length and frequency. Frequent words tend to be shorter in all languages. The Voynich text too adheres to Zipf’s law, which might suggest that it is in fact a natural language. But, since computer analyses did not result in a convincing match with any other language, probably not a known language with transliterated letters.
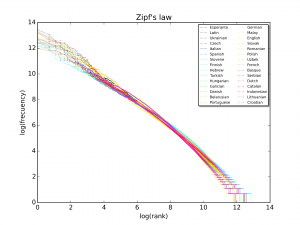
Could the text represent a more complicated cipher, i.e. a text in which each letter is replaced by another letter, but where the form of the letter is adjusted according to some rule, maybe shifting to a different code each line or each paragraph? This has been rejected by experts, as that should have led to a roughly equal distribution of the letters throughout the text, and that is clearly not the case either.
In short, despite the efforts of serious cryptographs, medievalists and linguists, no scholar or team of scholars has yet been able to crack the code, not even with the help of powerful computers.
And not only learned people have tried. Various nuts and cranks have made their attempts as well, and some even got their papers published in respected journals. These people have made some outrageous claims as well, not hindered by any form of knowledge.
In the beginning of this post I mentioned I was contacted by someone who claimed to have deciphered the manuscript. This person appears to be a research assistant in biology, and, after so much criticism came of his discovery, his university has distanced itself from its employee. The would-be biologist and linguistic crank argued (in his own viewed he actually proved) that it was written in a kind of creolized or mixed old Romance language. And since I am creolist, he wrote to me. Unfortunately, he really does not have a clue about linguistics, language change, typology, writing systems, phonology, linguistic terminology, or Romance languages, and lacks any skill necessary for serious linguistic analysis. His work is self-contradictory, fragmentary, and speculative. Simply put, he does not know what he is talking about. And this is why I do not even want to mention his name or work — he is simply not worth any attention.
Indeed, in this article I have thus far not included any links to anything having to do with the manuscript; people should just not waste their time trying to decipher it, as it is most likely a clever hoax. Who did it, and when and why, is what is interesting about it. I would however like to make an exception for this article, which presents a nice, objective and down-to-earth overview.
Almost all other things you find on the net are written by cranks. And there is a lot out there.
If you ask me, I believe that it is a very clever practical joke, a hoax, probably from the 15thcentury, the same date as the vellum and the ink. If it would have been a real language, in a rational and regular writing system, experts would have figured it out by now. There is so much text available, there are illustrations, such as the signs of the Zodiac, that provide clues to the contents. It should be easy to crack it. The mere fact that it has not been decoded, means that it is not decodable. It is simply a fake text.
Peter Bakker is a linguist at Aarhus University, interested in general properties of the languages of the world. He cannot crack the Voynich script, but he can crack most walnuts with his bare hands.
 Hvítasunnubrúðhlaupin – Philip Larkin’s best known poem found to be based on previously lost Old Norse manuscript
Hvítasunnubrúðhlaupin – Philip Larkin’s best known poem found to be based on previously lost Old Norse manuscript  Voynich-manuskriptet og dets dechifrering
Voynich-manuskriptet og dets dechifrering  Snow: the word’s effect
Snow: the word’s effect  A good sign! Myths about sign languages
A good sign! Myths about sign languages  Does he say he twice as often as she? Women, men and language
Does he say he twice as often as she? Women, men and language  The dictionary game: for learning and entertainment
The dictionary game: for learning and entertainment
See also the discussion about the above article here:
https://languagelog.ldc.upenn.edu/nll/?p=44374
A few points on the introductory section.
The Voynich manuscript is written on parchment. It’s on vellum – not uterine vellum but the finish is that of vellum, not of parchment. The spectrum between parchment and vellum can reach so fine and arguable a point that many now use the general term ‘membrane’. In this case, though, it matters because vellum was used for certain types of manuscript and other purposes for which parchment was inappropriate. It’s significant.
“dated to the first half of the 15th century” The dates gained by radiocarbon dating are 1404-1438. That’s important because many of the attempted ‘matches’ for the imagery come from the 1450s and later, and blurring the dates given by the University of Arizona allows lots of fudging.
The text and illustrations could be newer, but could be from the same time as well. I’d say that we have no physical evidence to suggest any long delay between manufacture of the vellum and its inscription.
Who wrote the manuscript? We assume it was written by a number of scribes. There is nothing to say – apart from the marked diversity in style of accompanying images – whether the informing text was gained from one or more previous texts – let alone who might have first composed each of those.
What is the meaning or reference of these strange drawings of dragons,
bathing naked ladies – it has been speculated that the images are to be read literally as women, and speculated too that they are to be imagined bathing. An entirely metaphorical, or allegorical intention is just as possible.
Maps of known and unknown places? I, myself, find only one map in the manuscript and no detail in it appears to be imaginary. However, much has been speculated and theorised in recent years.
Why are there no corrections in the manuscript? I believe that old idea has been corrected by more recent studies. Check Nick Pelling’s site, or look up the old mailing list for a start.
hi https://lh3.googleusercontent.com/urWLozPNSQz4KZBhte6AGms4fimdHhIQIfW9gRCGZS4mA_xyTO_l5o-m0dUkds_mkf2tXg=s85
can you check this link please and help me finding out the meaning of theses symbols
thank you
I would rather leave that to others who are more competent than I am. I also notice that the link does not work anymore.
“There is a correlation between word length and frequency.”
This is true, but this is not Zipf’s law. It’s explained correctly in the linked video. To summarize, Zipf’s law states that the number of occurrences of a specific word in a text is proportional to 1/n where n is the word’s ranking in the list of most frequent to less frequent word.
The correlation between word length and frequency is generally not as high as the correlation bound by Zipf’s law in most languages, but true it is there to some extent.
Thanks for this elaboration, Jonas.
There is a key to cipher the Voynich manuscript.
The key to the cipher manuscript placed in the manuscript. It is placed throughout the text. Part of the key hints is placed on the sheet 14. With her help was able to translate a few dozen words that are completely relevant to the theme sections.
The Voynich manuscript is not written with letters. It is written in signs. Characters replace the letters of the alphabet one of the ancient language. Moreover, in the text there are 2 levels of encryption. I figured out the key by which the first section could read the following words: hemp, wearing hemp; food, food (sheet 20 at the numbering on the Internet); to clean (gut), knowledge, perhaps the desire, to drink, sweet beverage (nectar), maturation (maturity), to consider, to believe (sheet 107); to drink; six; flourishing; increasing; intense; peas; sweet drink, nectar, etc. Is just the short words, 2-3 sign. To translate words with more than 2-3 characters requires knowledge of this ancient language. The fact that some symbols represent two letters. In the end, the word consisting of three characters can fit up to six letters. Three letters are superfluous. In the end, you need six characters to define the semantic word of three letters. Of course, without knowledge of this language make it very difficult even with a dictionary.
Much attention in the manuscript is paid to the health of women for the purpose of giving birth to healthy offspring.
And most important. In the manuscript there is information about “the Holy Grail”.
I am ready to share information, but only with those who are seriously interested in deciphering the Voynich manuscript.
Nikolai.
I am seriously interested in that the Voynich manuscript be deciphered, but I am highly skeptical of people who decipher a few words, especially if (1) letters can be freely omitted or added or exchanged (2) it is not known or revealed which “ancient language” it is written in. If someone, and that could be you, Nikolai, is able to translate a whole page, or even a hole paragraph, into a coherent text into, for example, English, showing the equivalents between “this ancient language” and some modern language, and with a coherent grammatical system fitting what we know about current and past languages, then I would be the first to applaud. On the basis of what you write, I am afraid that you are quite far from that. I wish you, and others, good luck.
You were inattentively reading my comment. I write that for a complete translation of the text, it is necessary to know this language perfectly. Even before you see the result of the decryption, you conclude that I am far away. It’s indecent.
Rereading your previous comment, even more attentively, I still conclude that you are far away from a translation of the manuscript. You have allegedly translated a few dozen unconnected words from a 100+ manuscript, and concluded on the basis of the pictures, what the topics of the manuscript are, and you have no clue what language the manuscript is written in. No sentence, paragraph or page has been translated. My statement is just a realistic comment.
i need that book pdf, i can decode it
Here it is:
https://www.holybooks.com/wp-content/uploads/Voynich-Manuscript.pdf
Good luck!
Been studying this manuscript for several years, had some luck translating 50 words into English, mostly from 4 pages, currently working with a transliteration file of the whole book, hope to find something on new pages when I plug in the 50 words, in the next few months. There are many clues and hints among the pages convincing to me that the book is self contained, no need for any external key. I believe the symbols can be manipulated in different ways to represent English letters. For example the symbol ‘8’ if you pretend it’s made of 2 coins and you flip each in different directions looking on edge can make the letter “T” if you flip both to the right can make the right side of a small “d” such ‘c8’ = cl also the ‘8’ could be an “i” as l , the symbol ‘g’ that appears at the end of many symbol groups are too numerous to be part of the words, (if we assume that every group is a word) then the ‘g’ has a special purpose, I believe it stands for “gravity” or the end of a gravitational field, hence a 2 letter word as ‘8g’ could be the English letter “I”. Another clue I will share from page 4, the flower on the right side straight down from the page number contains the letter “F” hence ‘4’ = “F” . Some self claimed experts will say that the page numbers are worthless because some pages have been moved around, but I disagree. Good luck to all.